
{kind=link}
Pod pojęciem „Routing dynamiczny” należy rozumieć grupę algorytmów, która odpowiada za prawidłową komunikację pomiędzy urządzeniami jakimi są routery, co umożliwia poznanie topografii danej sieci oraz wybór najbardziej optymalnej trasy od nadawcy do odbiorcy.
Routing dynamiczny składa się z następujących po sobie faz związanych ze zdobywaniem i analizowaniem informacji, czyli wprowadzaniem zmian w topografii sieci, odbieraniem i wysyłaniem informacji za pomocą aktywnego interfejsu, pozyskiwaniem informacji o innych sieciach poprzez wymianę informacji z innymi routerami, prowadzenie komunikacji z innymi routerami przy wykorzystaniu tego samego protokołu.
Wstęp
Ze względu na to, że większość ataków hakerskich realizowana jest przy użyciu sieci komputerowych, niezwykle istotne staje się zrozumienie zasad ich funkcjonowania, wymiany danych oraz samego bezpieczeństwa. Mając to na względzie niniejszym artykułem rozpoczynam cykl artykułów dedykowanych poszczególnym elementom sieci komputerowych, w tym ich bezpieczeństwu.
Aby zbytnio nie przeciągać wstępu, przejdę do krótkiego wyjaśnienia czym w zasadzie jest sieć komputerowa. Mianowicie pod pojęciem „sieci komputerowej” należy rozumieć cały system umożliwiający przesyłanie danych, komunikację oraz udostępnianie danych pomiędzy dwoma lub więcej połączonymi ze sobą komputerami za pomocą medium transmisyjnego. O samych sieciach komputerowych, ich topologiach (rodzajach) zarówno fizycznych, jak i logicznych, w tym zasadach przesyłu danych oraz typach mediów transmisyjnych będzie traktował jeden z kolejnych artykułów.
Skoro już mamy ogólnie zdefiniowane pojęcie sieci komputerowej, warto jeszcze przedstawić ogólną definicję routingu. Mianowicie „routing” to wybór optymalnej trasy przekazywania danych poprzez sieć lub sieci komputerowe od źródła (nadawcy danych) do celu (odbiorcy danych). Co do zasady routing dzieli się na statyczny i dynamiczny. Routing statyczny polega na ręcznym wybraniu najlepszej trasy przesyłu danych przez konkretnego administratora sieci. Natomiast routing dynamiczny polega na automatycznym wyborze takiej trasy przez konkretny router.
Bardziej szczegółowo o routingu dynamicznym
Jak wspomniałem powyżej routing dynamiczny polega na automatycznym wyborze trasy przesyłu danych od ich nadawcy (np. serwera) do ich odbiorcy (np. klienta, którym może być przeglądarka internetowa na konkretnym komputerze). Za wybór trasy odpowiada router, który komunikując się z innymi routerami samodzielnie wyznacza najbardziej optymalną trasę jaką będą musiały pokonać dane od ich nadawcy do odbiorcy. Ten model przesyłu danych, w świecie ciągle zmieniających się tras routingu oraz powstawania nowych ma swoje ogromne zalety, ponieważ odejmuje znaczną ilość pracy administratorowi sieci, który nie musi na bieżąco śledzić zmieniających się tras routingu oraz powstawania nowych. Minusem tego rozwiązania jest zmniejszenie bezpieczeństwa, zwiększenie ruchu sieciowego z uwagi na prowadzenie komunikacji pomiędzy routerami oraz wykorzystywanie większych zasobów procesora i pamięci. Jednakże z uwagi na rozwój sieci komputerowych oraz stale zwiększającą się pojemność zasobów sprzętowych i przepustowość łącz, a także szybkość wyboru najbardziej optymalnej trasy, ten model przesyłu danych stał się standardem w nowoczesnych sieciach komputerowych, w szczególności dużych i wielosegmentowych.
Routing dynamiczny byłby niemożliwy do zrealizowania, gdyby nie odpowiednie protokoły.
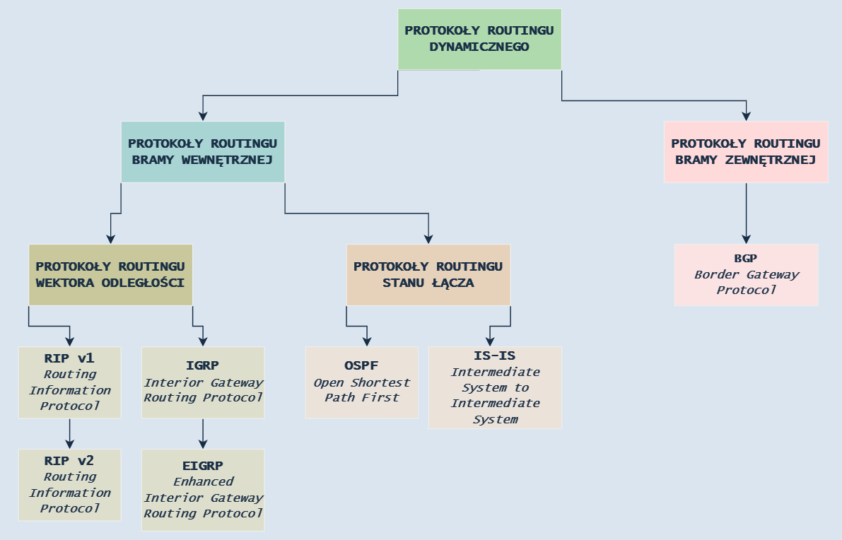
Ogólnie o protokołach routingu dynamicznego – podstawowy podział
Komunikacja sieciowa odbywa się za pomocą właściwych protokołów – nie inaczej jest w przypadku routingu dynamicznego. Protokoły routingu dynamicznego umożliwiają routerom odnajdywanie i utrzymywanie tras przesyłu danych, rozpoznawanie topologii poszczególnych sieci, czy sprawdzanie parametrów połączeń wykorzystywanych do obliczania i wyznaczania tras połączeń (przesyłu danych). Jednakże, aby komunikacja mogła zachodzić prawidłowo, routery używają komunikatów przenoszących informacje o zmianach w sieci (ang. routing update messages), których treścią są, w zależności od sytuacji, całe tablice routingu lub ich części.
Przykładowa tablica routingu w sieci lokalnej dla pojedynczego adresu IPv4 wygląda następująco:
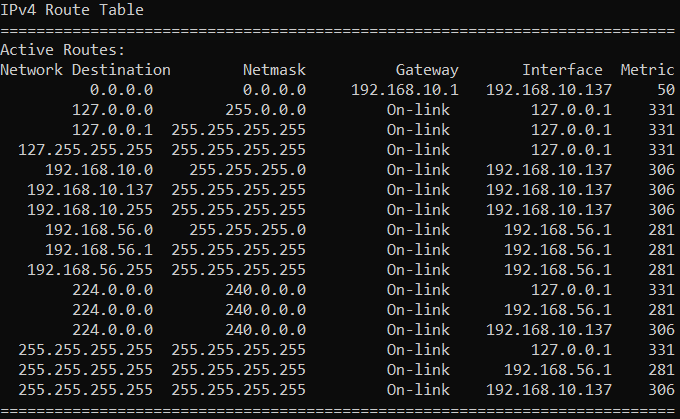
W wierszu poleceń systemu Windows można zobaczyć tablicę routingu używając polecenia route PRINT. Zgodnie z powyższym, możemy rozróżnić trzy klasy algorytmów routingu dynamicznego:
- Wektora odległości (wektorowo odległościowe, distance–vector) – algorytmy te odpowiadają za regularne wysyłanie przez router kompletnej zawartości tablicy routingu do wszystkich routerów sąsiednich. Natomiast sąsiednie routery przesyłają taką tablicę routingu dalej do kolejnych routerów. Z uwagi na zasadę działania ten rodzaj routingu nazywa się „routingiem przez plotkowanie”, ponieważ przesyłane są informacje nie tylko o sieci, w której dany router pracuje, ale informacje o sieciach przekazane są od sąsiednich routerów, co jest wykonywane na podstawie komunikacji rozgłoszeniowej (broadcast) i rzadziej na podstawie multiemisji (multicast). Natomiast zasadą działania tych algorytmów jest ogłaszanie poszczególnych tras jako wektorów zawierających informacje o odległości, która opisuje wyrażany za pomocą metryki koszt danej trasy oraz informacje o kierunku, który jest adresem kolejnego skoku. Stąd też pochodzi nazwa tej klasy routingu dynamicznego, czyli „wektor odległości”. W tym miejscu warto pokreślić, że dla tej klasy algorytmów istotna jest rozpiętość sieci, gdyż algorytmy te dedykowane są małym sieciom. Wyraża się to w tym, że jeżeli szerokość sieci jest wyższa niż maksymalna dopuszczalna w ramach konkretnego protokołu liczba skoków (hop), wówczas taka sieć oznaczana jest jako nieosiągalna. Natomiast niewątpliwym plusem sieci, w której model dynamicznego routingu opiera się o algorytmy wektorowo odległościowe jest prostota jego konfiguracji. Natomiast ta klasa dynamicznego routingu boryka się z istotnymi problemami. Pierwszym zasadniczym problemem jest wolne reagowanie na zmiany zachodzące w topologii sieci (problem zbieżności, czyli czas, w którym wszystkie routery w danej sieci mają spójne i uaktualnione informacje w swoich tablicach routingu), co np. wyraża się w uwidocznieniu po dłuższym czasie w tablicach routingu poszczególnych routerów zerwania łącza spowodowanego wyłączeniem pewnego segmentu sieci. Kolejnym problemem jest opisany powyżej „routing przez plotkowanie”, ponieważ routery generują dodatkowy ruch sieciowy przesyłając pomiędzy sobą kompletne tablice routingu, nawet wówczas, gdy w tych tablicach nie zaszły żadne zmiany. Ponadto protokoły należące do klasy wektora odległości podatne są na powstawanie pętli pomiędzy routerami sąsiadującymi, jak i znajdującymi się w sieciach odległych (pętle rozległe). Problem ten wyraża się we wzajemnym przesyłaniu przez routery informacji o tej samej sieci, lecz można mu zapobiegać poprzez stosowanie odpowiednich mechanizmów. Dodatkowo nie można zapominać o problemach związanych z propagacją błędnych informacji, ponieważ w tej klasie nie istnieją mechanizmy weryfikujące poprawność otrzymanej tabeli routingu, w związku z czym router, który otrzymał błędną tablicę routingu, będzie ją przekazywał kolejnym routerom. Jednakże jak wspomniałem powyżej, pomimo swoich wad, routing oparty na wektorze odległości, z uwagi na łatwość konfiguracji, warto stosować w małych sieciach. Algorytmy dla tej klasy zostały opracowane przez R.E Bellmana, L.R. Forda i D.R. Fulkersona i współpracują z protokołami RIP i IGRP, które szczegółowo są opisane poniżej.
- Stanu łącza – algorytmy te odpowiadają za przechowywanie w routerze bazy danych zawierającej informacje o stanie połączeń, o topologii sieci oraz o kosztach pojedynczych ścieżek w obrębie danej sieci. Informacje te są zbierane za pomocą rozsyłania pakietów LSA (link-state advertisement) służących do weryfikacji stanu łączy. Tak zebrane dane routery przesyłają między sobą, a każdy router pośredni zapisuje w swojej bazie danych informacje otrzymane od routera poprzedniego (kopię pakietów LSA), co sprawia, że po pewnym czasie, zwanym „czasem zbieżności” wszystkie routery mają tą samą mapę sieci (taką samą bazę danych o topologii sieci). Następnie każdy router pracujący w tej sieci tworzy drzewo SPF (najkrótszych ścieżek, shortest path first) do poszczególnych sieci, umieszczając siebie w centrum, czyli korzeniu tego drzewa. Wybierając ścieżkę, router opiera się o koszt dotarcia do sieci docelowej, co oznacza, że wybrana najkrótsza trasa nie musi być trasą o najmniejszej liczbie skoków (routerów pośredniczących). Wybór ścieżki odbywa się za pomocą algorytmu opracowanego przez E.W. Dijkstry’ego. Niewątpliwą zaletą algorytmów stanu łącza jest znacznie większa odporność (w stosunku do algorytmów wektora odległości) na błędy polegające na propagacji nieprawidłowych danych o sieci, gdyż każdy z routerów pracujących w danej sieci ma identyczną bazę danych zawierającą informacje o tej sieci, a dzięki zastosowaniu drzewa SPF został wykluczony problem rozległych pętli, o których wspomniałem powyżej omawiając algorytmy wektora odległości. Warto dodać, że niewątpliwa zaletą algorytmów stanu łącza jest szybkie reagowanie na zmiany w topologii sieci, co wyraża się w tym, że jeśli router wykryje taką zmianę, to generuje nowy pakiet LSA i rozsyła go do pozostałych routerów (także routery rozsyłają go pomiędzy sobą). Każdy router otrzymujący taki pakiet LSA na nowo przelicza drzewo SPF i na jego podstawie aktualizuje swoją tablicę routingu. W związku z tym unika się niepotrzebnego ruchu sieciowego polegającego na cyklicznym rozsyłaniu pomiędzy routerami swoich tablic routingu, wobec czego protokoły pracujące w tej klasie określane są mianem protokołów „cichych”. Z uwagi na sposób przekazywania informacji o sieci pomiędzy routerami oparcie dynamicznego routingu na tej klasie dedykowane jest dużym sieciom. Omawiając klasę stanu łącza nie można pominąć też jej wad. Główną wadą jest zwiększony ruch sieciowy, wymagający odpowiednio szerokiego łącza w fazie przekazywania pomiędzy routerami pakietu LSA, czyli zanim routery „ucichną”. Drugą wadą, którą warto tutaj wymienić, jest zwiększone zapotrzebowanie routerów na pamięć RAM i zwiększone wymagania dotyczące wydajności procesora, co jest spowodowane złożonością obliczeń drzewa SPF, które każdy router musi przeprowadzić po każdej zmianie w sieci. Podstawowym i głównym protokołem pracującym w tej klasie jest szczegółowo opisany poniżej protokół OSPF.
- Klasowe – algorytmy te działając na podstawie właściwych protokołów, nie ogłaszają maski podsieci razem z adresem sieci, w związku z czym jeśli interfejs routera odbierającego ma adres IP z tej samej sieci głównej, co sieć ogłaszana, wówczas może zastosować maskę podsieci z własnego interfejsu. W przypadku protokołów klasowych sposób ogłaszania tras do routerów sąsiednich znacznie różni się od opisanych powyżej protokołów z klas wektora odległości i stanu łącza. Opiera się on na porównaniu sieci głównej w ramach poszczególnych podsieci. Innymi słowy możemy rozróżnić trzy sytuacje.
Pierwsza sytuacja zachodzi jeżeli podsieć oraz interfejs ogłaszający tą podsieć mają taką samą sieć główną oraz jednakowej długości maskę podsieci – w takim przypadku sieć będzie poprawnie ogłaszana, ale tylko z użyciem poprawnego adresu IP sieci, lecz bez uwzględnienia jej maski podsieci. Dla zobrazowania tej sytuacji można posłużyć się przykładem, w którym router ogłasza przez swój interfejs S0 podsieć 172.16.10.0, a router otrzymujący to ogłoszenie interpretuje je z użyciem maski podsieci własnego interfejsu S0.
Natomiast druga sytuacja zachodzi, jeżeli podsieć ma taką samą sieć główną jak interfejs, przez który ta podsieć jest ogłaszana, lecz posiada inną maskę podsieci – wówczas router nie będzie ogłaszał takiej podsieci. Dla zobrazowania tej sytuacji można posłużyć się przykładem: jeśli maska podsieci 172.16.10.0 będzie miała np. 24 bity i jest niezgodna z np. 30-bitową maską interfejsu S0, wówczas router nie będzie ogłaszał podsieci przez ten interfejs. Trzecia sytuacja zachodzi wówczas, gdy ogłaszana podsieć ma inną sieć główną niż interfejs, przez który ta podsieć jest ogłaszana. Wówczas router, który wysyła ogłoszenie, dokonuje automatycznego przekształcenia adresu ogłaszanej podsieci na adres sieci głównej, co nazywa się łączeniem tras na granicy sieci głównych i jest przedstawione na poniższym rysunku: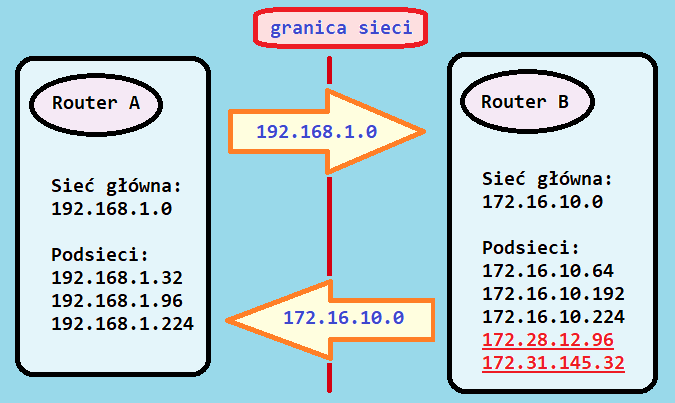
Fot. Michał Mamica W tym miejscu warto zaznaczyć, że protokoły klasowe nie obsługują sieci nieciągłych, czyli dwóch podsieci tej samej sieci głównej, ale rozdzielonych inną siecią główną, co widać na obu poniższych rysunkach:
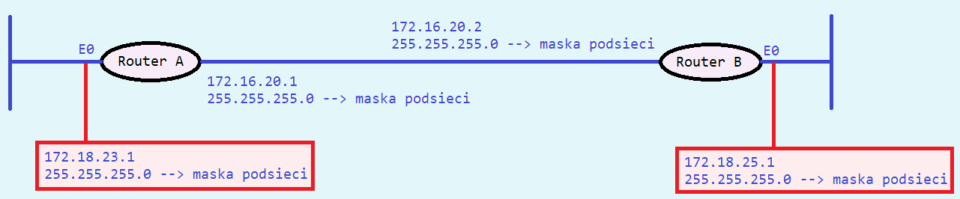
Fot. Michał Mamica W tym przypadku interfejsy Ethernet (oznaczone na rysunku „E0”) routerów A i B mają przypisane adresy IP dwóch różnych podsieci z sieci głównej 172.18.0.0. Natomiast na interfejsach szeregowych łączących routery wykorzystywana jest sieć główna 172.16.0.0. W takim przypadku router A ogłaszając swoją sieć 172.18.23.0 routerowi B dokona przekształcenia na adres wynikający z klasy z uwagi na granicę sieci głównych. W takim przypadku ogłoszenie sumaryczne docierające do routera B jest ignorowane przez ten router, ponieważ ma on dokładniejsze informacje o sieci 172.18.0.0, ponieważ jest lokalnie podłączony do podsieci 172.18.25.0. Tak samo wygląda ogłaszanie swojej sieci 172.18.25.0 przez router B, routerowi A. Prowadzi to do sytuacji, w której ani router A ani router B nie będą miału w swoich tablicach routingu informacji o adresach IP w podsieciach stosowanych w segmentach LAN sąsiedniego routera (A i B).
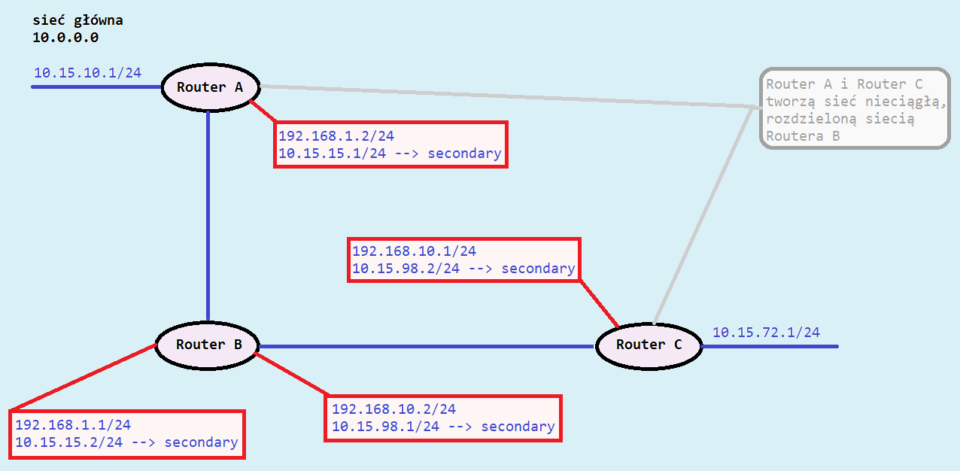
Fot. Michał Mamica Ten problem można rozwiązać stosując protokół bezklasowy, który dzięki dodatkowemu ogłaszaniu maski podsieci umożliwia wyłączenie automatycznego łączenia tras na granicy sieci głównych. Jest to możliwe, ponieważ ogłaszana jest poprawna długość podsieci, a router, który odebrał połączenie zapisuje w swojej tablicy routingu adres IP sieci o poprawnej długości. W sieciach nieciągłych istnieje też możliwość posłużenia się drugorzędnymi adresami IP (na poniższym rysunku opisanymi „secondary”) należącymi do tej samej sieci głównej co nieciągłe podsieci. Co istotne, aby była możliwa prawidłowa komunikacja z wykorzystaniem adresów drugorzędnych, koniecznie należy je przypisać do wszystkich interfejsów znajdujących się na trasie pomiędzy podsieciami nieciągłymi.
W naszym przykładzie przedstawionym na powyższym rysunku drugorzędną siecią główną jest sieć 10.0.0.0, która składa się z dwóch podsieci, mianowicie 10.15.10.0 (za routerem A) oraz 10.15.72.0 (za routerem C). Jest to przykład sieci nieciągłej, ponieważ rozdzielona jest ona dwoma sieciami głównymi 192.168.10.0 oraz 192.168.1.0. Jednakże dzięki przypisaniu adresów drugorzędnych, które należą do dwóch różnych podsieci tej samej sieci głównej, czyli 10.0.0.0, ogłaszanie informacji przez poszczególne interfejsy routerów na trasie pomiędzy routerem A i routerem C nie wymaga łączenia tras routingu na granicy sieci głównych rozdzielających sieć 10.0.0.0. Warto zaznaczyć, że w naszym przykładowym modelu zachodzi dwukrotny proces ogłaszania, który jest niezależny dla adresu głównego i adresu drugorzędnego. Jest to spowodowane przypisaniem dwóch adresów IP do jednego interfejsu, czyli adresu głównego i adresu drugorzędnego.
W związku z tym, że klasy routingu dynamicznego są ściśle powiązane z protokołami routingu, na poniższym diagramie przedstawiam jak wygląda umiejscowienie w sieci poszczególnych protokołów:
Protokół RIP
Protokół RIP (Routing Information Protocol) jest jednym z najstarszych protokołów routingu. Zwany inaczej protokołem bram wewnętrznych został oparty na zestawie algorytmów wektorowych (opisanej powyżej klasie wektora odległości), służących do obliczenia najlepszej trasy od nadawcy danych do celu, czyli ich odbiorcy. Obecnie protokół RIP jest najczęściej stosowany jako protokół wewnętrzny IGP (Interior Gateway Protocol), ale także jest wykorzystywany w sieciach rozległych przy wykorzystaniu protokołu EGP (Exterior Gateway Protocol).
Protokół RIP po raz pierwszy został użyty w 1982 roku, ale część jego podstawowych algorytmów pamięta czasy sieci ARPANET wykorzystywanej od 1969 roku. Jednakże w mechanice swojego działania protokół RIP wykorzystuje algorytm Forda-Bellmanna. Protokół ten rozwinął się z opracowanego przez firmę Xerox protokołu GWINFO (Gateway Information Protocol) i wraz z rozwojem systemu XNS (Xerox Network Systems) przekształcił się (w 1982 roku) w protokół RIP.
Protokół RIP został opisany w dwóch dokumentach RFC (Request For Comments), czyli RFC 1058 dla RIP w wersji 1 i RFC 2453 dla RIP w wersji 2.
Opierając się na protokole RIP, routery wymieniają między sobą informacje o trasach routingu do innych routerów i na ich podstawie aktualizują swoje tablice routingu, w określonych przedziałach czasu rozsyłają informacje o swojej obecności oraz informują o posiadanej aktualnej informacji połączeń międzysieciowych i rozsyłają informacje o wykrytych zmianach w konfiguracji sieci.
Cechą charakterystyczną protokołu RIP jest optymalizacja wyboru trasy z uwzględnieniem kryterium najmniejszej liczby skoków (przejść przez kolejne routery na drodze od źródła do celu).
Używany jest on zazwyczaj do łączenia małych sieci komputerowych, co jest spowodowane ograniczoną wartością metryki oraz prostotą konfiguracji tego protokołu. Warto nadmienić, że jak każdy protokół należący do klasy wektora odległości, ten protokół wysyła dane do sąsiednich routerów cyklicznie, co 30 sekund – nazywa się to wysyłaniem aktualizacji okresowych (periodic updates). W ramach aktualizacji okresowych, korzystający z protokołu RIP router wysyła całą tablicę routingu do sąsiednich routerów, niezależnie od zmian w topologii sieci.
Jak wspomniałem powyżej, protokół RIP wstępuje w dwóch wersjach, których cechy prezentuję na poniższych rysunkach:
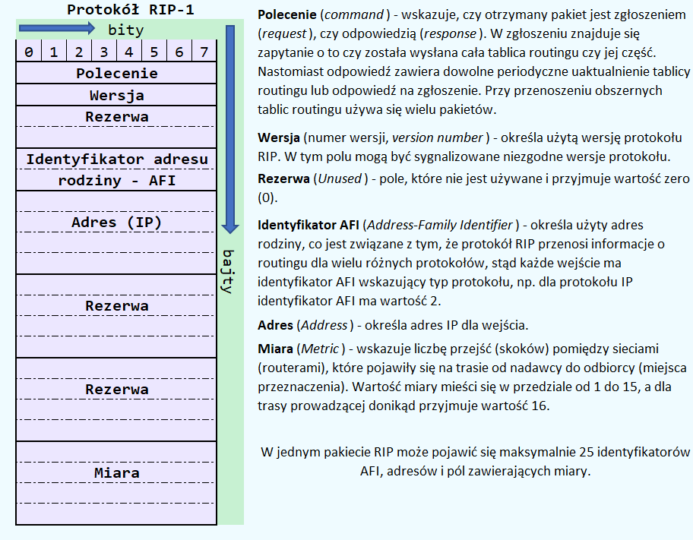
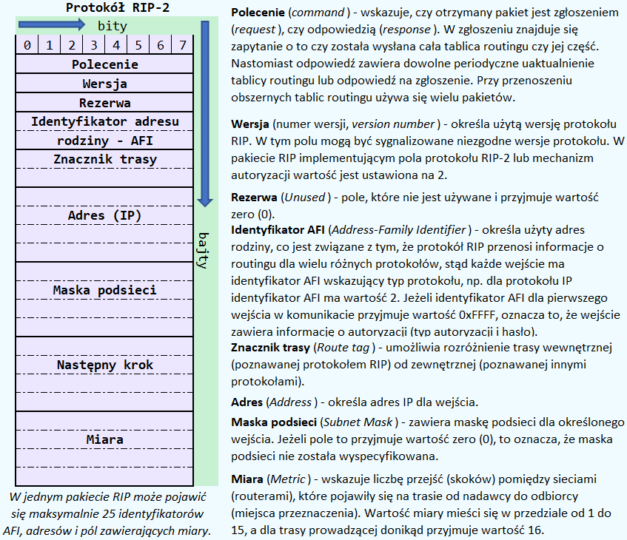
W tym miejscu warto dodać, że do mierzenia odległości pomiędzy nadawcą a odbiorcą służy zliczanie skoków (hop-count), czyli przejść pomiędzy routerami. Każdemu skokowi nadawana jest określona wartość – najczęściej „1”. Jeżeli natomiast router otrzyma uaktualnienie routingu, które zawiera nowe lub zmienione wejście i jeśli po zwiększeniu miary o „1” nastąpi przekroczenie granicy 15 skoków, to pakiet nie zostaje przesłany dalej. Rozwiązanie to zapobiega tworzeniu nieskończonych pętli, w których dane byłyby przesyłane bez końca i nigdy by nie dotarły do punktu końcowego (odbiorcy).
Ponadto, w celu dostosowania do szybkich zmian w topologii sieci, protokół RIP zawiera mechanizmy stabilizujące, takie jak split-horizon oraz hold-down, które zapobiegają negatywnym skutkom błędnych informacji o routingu. Dodatkowo dostosowując protokół RIP do potrzeb wydajności routingu, został on wyposażony w czasomierze (timers), do których można zaliczyć:
- Czasomierz uaktualnienia routingu (routing-update timer), który wyznacza przedziały czasu pomiędzy kolejnymi okresami uaktualniania,
- Limitu czasu trasy (route-timeout timer), który jest przypisany do każdego wejścia do tablicy routingu,
- Czyszczenia trasy (route-flush timer), który czyści tablicę routingu jako nieważną, po wyczerpaniu czasu pracy czasomierza limitu czasu pracy.
W tym miejscu warto jeszcze wskazać na podobieństwa i różnice w obu wersjach protokołu RIP. Do podstawowych podobieństw należy zaliczyć brak możliwości równoważenia obciążenia poprzez nadmiarowe (rezerwowe łącza), długi czas osiągania zbieżności tablic routingu, przenoszenie uaktualnień za pomocą protokołu UDP na porcie 520, ten sam dystans administracyjny (120), a także tworzenie i aktualizowanie tablic routingu rozproszoną metodą (algorytmem) Forda-Bellmanna.
Natomiast podstawowymi różnicami są:
- protokół RIPv1 nie obsługuje bezklasowego routingu, podczas gdy protokół RIPv2 obsługuje bezklasowy routing,
- protokół RIPv1 nie obsługuje autentyfikacji, podczas gdy protokół RIPv2 zapewnia wsparcie dla uwierzytelniania routera oraz wiadomości stosując haszowanie algorytmem MD5 używającym 128-bitowej funkcji skrótu,
- protokół RIPv1 używa adresu rozgłoszeniowego 255.255.255.255, podczas gdy protokół RIPv2 automatycznie wysyła aktualizacje routingu jako komunikat multicastowy na adres 224.0.0.9, co powoduje eliminację ruchu przez hosty nieroutujące,
- protokół RIPv1 zawsze dokonuje automatycznej sumaryzacji na granicy sieci głównych, podczas gdy protokół RIPv2 dokonuje domyślnie automatycznej sumaryzacji na granicy sieci głównych.
Protokół OSPF
Protokół OSPF (Open Shortest Path First), co w wolnym tłumaczeniu oznacza „pierwszeństwo ma najkrótsza ścieżka”, jest protokołem trasowania opartym na analizie stanu łącza (link-state), a zarazem wchodzi w skład protokołów IGP, czyli bramy wewnętrznej. Został on zdefiniowany przez IETF (Internet Engineering Task Force) i opisany w dokumencie RFC 1247 w wersji drugiej oraz w RFC 2328 dla protokołu IPv4 oraz w RFC 5430 dla protokołu IPv6. Protokół OSPF odpowiada za kontrolę przepływu pakietów wewnątrz obszarów, czyli systemów autonomicznych (AS), które są definiowane jako grupa routerów wymieniająca się informacjami o routingu z wykorzystaniem tego protokołu.
Na marginesie warto dodać, że autonomicznym systemem (Autonomous System, AS) nazywany jest obszar sieci komputerowej, tj. ustalony zbiór prefiksów IP, będący pod wspólną administracją, posiadający wspólną politykę routingu i dostępu do Internetu. Każdy system autonomiczny posiada swój unikalny 16 lub 32 bitowy identyfikator ASN (Autonomous System Number).
Protokół OSPF charakteryzuje się dobrą skalowalnością, wyborem optymalnych tras, przyspieszoną zbieżnością oraz brakiem ograniczania skoków (powyżej 15). Protokół ten używa hierarchicznej struktury sieci z podziałem na obszary (które nie powinny liczyć więcej niż 50 routerów), z centralnie umieszczonym obszarem zerowym (area 0). Area 0 pośredniczy w wymianie tras między wszystkimi obszarami w danej domenie OSPF i umożliwia trasowanie pakietów pomiędzy obszarami bez stosowania pętli. Natomiast routery, po dokonaniu przeliczenia nowych tras, informują się o zmianie topologii obszaru poprzez zalewanie (flooding).
Routery korzystające z protokołu OSPF porozumiewają się ze sobą za pomocą pięciu komunikatów (pakietów), czyli:
- hello – komunikat ten odpowiada za nawiązanie i utrzymanie relacji z sąsiednimi routerami,
- database descriptions – komunikat ten odpowiada za opis przechowywanych baz danych,
- requests link-state – komunikat ten odpowiada za żądanie informacji na temat stanów połączeń,
- updates link-state – komunikat ten odpowiada za aktualizację stanów połączeń,
- acknowledgments link-state – komunikat ten odpowiada za potwierdzanie stanów połączeń.
W tym miejscu należy wyraźnie podkreślić, że protokół OSPF jest protokołem typu link-state jedynie wewnątrz określonego obszaru, natomiast pomiędzy obszarami OSPF działa jako protokół typu distance-vector, co oznacza, że routery brzegowe obszarów wymieniają się miedzy sobą gotowymi trasami.
Routerem brzegowym, zwanym inaczej routerem obszaru granicznego (Area Border Router, ABR), jest ten, który należy do określonego obszaru, a zarazem sąsiaduje z drugim obszarem. Pełni on istotną rolę, ponieważ przechowuje tabele routingu dla dwóch sąsiadujących obszarów. Niemniej jednak zalecane jest, aby w jednym routerze brzegowym były przechowywane maksymalnie trzy tablice routingu, co jest podyktowane minimalizacją wykorzystania zasobów takiego routera i zachowania ich na przeliczanie tras w przypadku ich zmian oraz na dystrybucję aktualnych informacji o stanie łączy.
Warto dodać, że w celu zmniejszenia liczby pakietów rozsyłanych w sieci, w obrębie sieci lokalnej (LAN) wybierany jest router desygnowany (designated router, DR) oraz router zapasowy (backup designated router, BDR), których zadaniem jest wymiana informacji o stanie łączy z pozostałymi routerami. Routery pracujące w tej samej sieci pobierają informacje o trasach z routera desygnowanego, jeżeli ich tablice ARP (routingu) nie zawierają wpisu o trasie do określonej lokalizacji docelowej. W tym przypadku komunikat hello służy do wyboru routera DR lub BDR oraz do wykrywania nieaktywnych sąsiednich routerów.
Pomimo, że możemy wyróżnić trzy wersje protokołu OSPF, czyli OSPFv1, OSPFv2 (dla IPv4) oraz OSPFv3 (dla IPv6), to nagłówek tego protokołu jest jednakowy dla wszystkich trzech wersji i wygląda następująco:
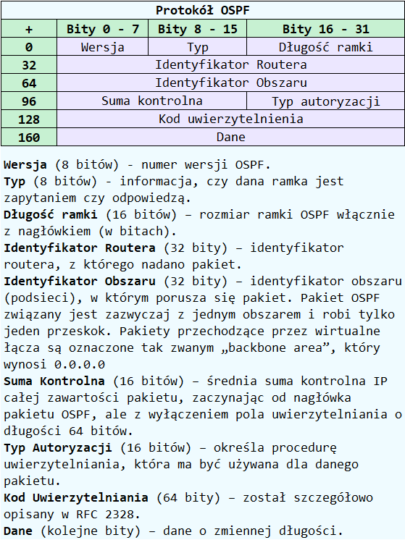
W tym miejscu należy dodać, że na podstawie protokołu OSPF mogą być budowane sieci szkieletowe, składające się maksymalnie z 50 routerów połączonych ze sobą bezpośrednio, co wynika z koncepcji hierarchiczności sieci oraz umożliwia zarządzanie aktualizacjami tras routingu w obrębie sieci szkieletowej.
Ponadto przy wykorzystaniu protokołu OSPF można tworzyć wirtualne połączenia pomiędzy routerami za pośrednictwem trzeciego routera, który nie należy do obszaru, w którym pracują dwa pozostałe routery. Wirtualne połączenia mogą tworzyć obejścia wykorzystywane w przypadku wystąpienia awarii głównych łączy w obrębie określonego obszaru.
Natomiast sam obszar musi składać się z routerów, które tworzą sieć ciągłą zarówno pod względem połączeń pomiędzy routerami, jak również w odniesieniu do przestrzeni adresowej, co umożliwia sumaryzację sieci (jej agregację). Warto dodać, że protokół OSPF wspiera VLSM (Variable Length Subnet Mask), czyli możliwość podziału i rozróżnienia dodatkowych podsieci z już istniejących podsieci, dzięki czemu może zostać zmaksymalizowana agregacja sieci w sieci szkieletowej i na routerach ABR.
Warto dodać, że agregacja sieci zwiększa jej stabilność i jest konfigurowana (określana) na routerach ABR. Jednakże, aby korzystać ze wszystkich zalet agregacji, w pierwszej kolejności należy dokonać jej optymalizacji poprzez zdefiniowanie schematu adresacji oraz zakresu adresów poszczególnych podsieci wykorzystywanych w każdym obszarze składającym się z routerów połączonych ze sobą w sposób ciągły. Następnie powinno się stosować maski VLSM, aby maksymalnie wykorzystać dostępną przestrzeń adresową. Ponadto projektując sieć należy zaplanować jej dalszy rozwój, w tym poprzez dodanie nowych routerów, i odpowiednio zdefiniować przestrzeń adresową w ramach tej sieci.
Pomimo że protokół OSPF należy do dynamicznych protokołów routingu, to sama agregacja sieci musi być ręcznie skonfigurowana, co obejmuje określenie informacji o każdym obszarze w danej sieci szkieletowej oraz informacji o trasach routingu istniejących w danym obszarze.
Co istotne, same obszary oparte na protokole OSPF zawierają następujące informacje o trasach routingu:
- default – jest to informacja o domyślnej trasie dla wszystkich pakietów, których docelowy adres IP lub docelowa podsieć nie została znaleziona w tablicach routingu,
- intra-area – jest to informacja o trasach danych sieci lub podsieci w obrębie określonego obszaru,
- interarea – jest to informacja dedykowana dla konkretnego obszaru, która zawiera informacje o konkretnych sieciach lub podsieciach w autonomicznym systemie (AS), znajdującym się poza obszarem, do którego kierowana jest ta informacja,
- external – jest to informacja o trasach obliczonych w wyniku wymiany wiadomości o routingu pomiędzy autonomicznymi systemami (AS) – są to trasy zewnętrzne dla danego systemu autonomicznego (AS).
Natomiast same obszary możemy podzielić na obszary na końcu gałęzi, obszary z więcej niż jednym połączeniem oraz obszary bez agregacji.
Obszar na końcu gałęzi, czyli podłączony tylko do jednego innego obszaru OSPF, wykorzystuje wbudowane domyślne trasy (default) oraz trasy intra-area i interarea. Obszaru tego nie można wykorzystywać do tworzenia wirtualnych połączeń, jak też nie może on wykorzystywać routerów brzegowych autonomicznego systemu (AS).
Obszar z więcej niż jednym połączeniem wykorzystuje wbudowane domyślne trasy (default), trasy intra-area i interarea oraz trasy zewnętrzne (external) i jest połączony z innymi obszarami OSPF. Ponadto obszar ten wykorzystuje routery brzegowe obszaru granicznego autonomicznego systemu (AS). Jednocześnie mogą w takim obszarze być ustanawiane połączenia wirtualne.
Obszar bez agregacji wykorzystuje wbudowane domyślne trasy (default) oraz trasy intra-area i jest zalecany jedynie w przypadku zastosowania pojedynczego połączenia routera z siecią szkieletową.
Natomiast wybór tras w oparciu o protokół OSPF dokonuje się na podstawie metryki przepustowości, która jest definiowana w oparciu o wykorzystywane medium transmisyjne. Sama metryka przepustowości danego łącza jest odwrotnością jego przepustowości. Może to brzmi dziwnie, ale mechanizm jest stosunkowo prosty. Metrykę przepustowości oblicza się na podstawie mechanizmu FDDI (Fiber Distributed Data Interface), który ma domyślnie przypisaną wartość 1 i taką wartość otrzymują media transmisyjne zapewniające przepustowość większą niż 100 Mb/s. Całkowita metryka dla danej trasy jest sumą wszystkich metryk przepustowości poszczególnych łączy tworzących określoną trasę. Jeżeli sieć jest agregowana, to wykorzystywana jest trasa zawarta w najlepszej metryce, aby zapewnić jak najszybszy przesył danych od ich nadawcy do miejsca docelowego.
Protokół OSPF jako protokół stanu łącza wykrywa zmiany w sieci na podstawie zmian statusów interfejsów lub występowania błędów, czyli braku odpowiedzi przy wysyłaniu komunikatu hello do sąsiedniego routera. Domyślnie licznik czasu (oczekiwania na odpowiedź) ustawiony jest na 40 sekund w sieciach LAN (w sieciach z rozgłaszaniem) oraz 120 sekund w sieciach niewykorzystujących rozgłaszania (sieciach WAN). W przypadku wykrycia uszkodzonego łącza, router samodzielnie przelicza nową trasę oraz wysyła pakiet, do wszystkich routerów znajdujących się w danym obszarze, zawierający informację o zmianie stanu łącza. Wówczas każdy router z danego obszaru dokonuje ponownego przeliczenia swojej tablicy routingu.
Ponadto skalowalność opierająca się na liczbie obszarów i liczbie łączy w sieci wykorzystującej protokół OSPF pozwala ograniczyć wykorzystanie przepustowości łączy w porównaniu do protokołów wektora odległości, takich jak RIP czy IGRP.
Na zakończenie podkreślić należy, że protokół OSPF ma wbudowany mechanizm bezpieczeństwa, którym jest uwierzytelnianie w celu weryfikacji czy łączący się sąsiedni router rzeczywiście należy do danej sieci. Uwierzytelnianie chroni przed nieuprawnionym i nieupoważnionym dostępem do sieci i pracujących w niej routerów, jak też pomaga zapewnić stabilne działanie całej sieci.
Protokół IGRP
Protokół IGRP (Interior Gateway Routing Protocol) jest protokołem trasowania klasowego (opartego na klasach sieci) bramy wewnętrznej i wymiany informacji o trasach routingu, opracowanym przez Cisco. W wchodzi w skład grupy protokołów sieciowych kontrolujących przepływ pakietów wewnątrz systemu autonomicznego (AS). Obecnie protokół ten nie jest już wspierany przez Cisco (od systemu operacyjnego 12.3). Celem jego stworzenia było ominięcie ograniczeń protokołu RIP, które występowały w dużych sieciach komputerowych, w tym minimalizacja pętli routingu i wdrożenie zarządzania błędami.
Protokół IGRP mogą stosować routery pracujące w jednej sieci lub w autonomicznym systemie (AS), a tablice routingu współpracujących routerów są aktualizowane za każdym razem, gdy zmieni się topologia sieci.
Ponadto protokół ten odpowiada za utrzymywanie tablic routingu z najbardziej optymalnymi trasami do odpowiednich węzłów i sieci w sieciach nadrzędnych, zgodnie z jej ustawieniami, a jako że jest protokołem wektora odległości (distance-vector) oblicza (24-bitową) metrykę najkrótszej trasy do określonego miejsca docelowego. W tym celu dokonuje pomiarów: przepustowości, domyślnych opóźnień, niezawodności tras, obciążenia łącz oraz MTU. Routery pracujące na podstawie tego protokołu standardowo wysyłają aktualizacje tras co 90 sekund z czasem przetrzymywania (czasem pomiędzy sesjami nadawczymi) wynoszącym 280 sekund. Jednakże w przypadku wykrycia zmian w sieci wykorzystywane są wyzwalane aktualizacje w celu przyspieszenia procesu konwergencji i jak najszybszej aktualizacji tablic routingu sąsiednich routerów znajdujących się w tym samym autonomicznym systemie (AS). Warto dodać, że maksymalna liczna skoków (hops) w protokole IGRP wynosi 255, lecz domyślnie jest ustawiona na 100.
Ponadto protokół ten używa Zegarów IGRP, czyli liczników czasu, które są używane w Internecie rzeczy (IoT).
Jak wspomniałem powyżej, routery komunikujące się na podstawie protokołu IGRP cyklicznie przesyłają aktualizacje tablic routingu swoim sąsiadom. Jest to zarówno zaleta (mniejsze obciążenie łącz w porównaniu do protokołu RIP), jak też i wada. Wynika to stąd, że po 270 sekundach (trzykrotność 90-sekundowego licznika aktualizacji) protokół IGRP wykorzystuje nieprawidłowy licznik czasu do sklasyfikowania trasy jako nieaktualnej. Następnie do usunięcia trasy z tablicy routingu wykorzystywany jest licznik czasu opóźnienia, tak samo jak w protokole RIP. Domyślny czas usunięcia nieaktualnej trasy ustawiony jest na 630 sekund (ponad 10 minut), co oznacza, że jest aż siedem razy dłuższy niż czas aktualizacji, co jest bardzo poważną wadą tego protokołu.
Natomiast w przypadku awarii sieci lub wzrostu metryki sieci, router nie akceptuje żadnych nowych modyfikacji trasy do momentu upłynięcia czasu wstrzymania, który jest domyślnie ustawiony na 280 sekund, czyli trzykrotność licznika aktualizacji plus 10 sekund. Taka konfiguracja protokołu IGRP ma na celu zapobieżenie pętli routingu.
Na zakończenie należy dodać, iż protokół ten nie jest protokołem otwartym, lecz można z niego korzystać na określonych urządzeniach firmy Cisco, posiadając odpowiednią licencję.
Protokół EIGRP
Protokół EIGRP (Enhanced Interior Gateway Routing Protocol) jest hybrydowym protokołem trasowania bezklasowego opracowanym przez firmę Cisco. Celem utworzenia tego protokołu było połączenie zalet protokołów wektora odległości z zaletami protokołów stanu łącza. Dodatkowo umożliwia on obsługę protokołów, takich jak IP, Novell NetWare IPX, czy Apple Talk.
Niewątpliwymi zaletami tego protokołu jest obsługa bezklasowego routingu międzydomenowego oraz techniki VLSM, o której wspomniałem wyżej opisując protokół OSPF, a także zbieżność, skalowalność i zarządzanie pętlami routingu.
Protokół EIGRP dedykowany jest sieciom komputerowym składającym się z maksymalnie 50 routerów i korzystających z wielu różnych protokołów, jednocześnie zapewniając zgodność ze starszym protokołem IGRP. Obliczana metryka najkrótszej trasy ma 32 bity długości, dzięki czemu wybór odpowiedniej trasy dokonywany jest znacznie bardziej efektywnie niż w przypadku protokołu IGRP.
Co istotne, protokół EIGRP przechowuje informacje o trasach i topologii sieci w pamięci RAM routerów, co umożliwia szybką reakcję na zmiany tras. Dodatkowo informacje o trasach przechowywane są w trzech tablicach, którymi odpowiednio są:
- Tablica sąsiadów, zawierająca informację o sąsiadujących routerach, przy czym dla każdego protokołu obsługiwanego przez protokół EIGRP tworzona jest osobna tablica sąsiadów. Natomiast zmiany w tablicy sąsiadów zachodzą w razie wykrycia nowego sąsiedniego routera, którego dane zapisywane są w strukturze danych urządzeń sąsiadujących i są tam przechowywane przez czas przetrzymywania, czyli czas, przez jaki router uważa swojego sąsiada za dostępnego i działającego. Jeżeli w czasie przetrzymywania sąsiad nie wyśle kolejnego pakietu (komunikatu) hello (domyślnie komunikaty te wysyłane są co 5 sekund), wówczas czas przetrzymywania wygasa, a router musi ponownie obliczyć nową trasę i poinformować o zmianach w topologii sieci, co odbywa się na podstawie algorytmu DUAL opartego na wektorze odległości; co istotne możliwe jest ponowne odtworzenie trasy, która została uznana za już nieistniejącą.
- Tablica topologii jest tworzona ze wszystkich tablic routingu w autonomicznym systemie (AS). Zawiera następujące pola:
- Opłacalna odległość FD – czyli najniższa obliczona metryka do każdego miejsca docelowego,
- Miejsce źródłowe trasy – czyli numer identyfikacyjny routera ogłaszającego jako pierwszy daną trasę; pole to jest wypełniane jedynie wówczas, gdy router otrzymał informację o trasie spoza sieci EIGRP (z zewnątrz), co jest szczególnie przydatne w routingu opierającym się na regułach,
- Zgłaszana odległość RD (Reported Distance) – czyli odległość od miejsca docelowego podawana przez sąsiada (sąsiedni przylegający router),
- Informacje o interfejsie – czyli w polu tym zawarte są dane dotyczące interfejsu, za pośrednictwem którego możliwe jest dotarcie do miejsca docelowego,
- Stan trasy – czyli w polu tym zawarte są informacje o stanie w jakim znajduje się określona trasa; trasy mogą przyjmować dwa stany, czyli być rozpoznane jako pasywne (stabilne i gotowe do użycia) lub aktywne (w trakcie obliczania przez algorytm DUAL).
Warto dodać że w tablicy topologii zapisywane są także trasy zastępcze (Feasible Successor Route, FS), które traktowane są jako zapasowe, lecz nie są one przekazywane do tablicy routingu.
- Tablica routingu zawiera informacje o najlepszych trasach do określonych miejsc docelowych, a informacje o trasach pobierane są z tablicy topologii. Co ciekawe, routery pracujące w oparciu o protokół EIGRP przechowują osobne tablice routingu dla każdego protokołu sieciowego. W tablicy routingu dla danego miejsca docelowego mogą być przechowywane maksymalnie cztery trasy główne, charakteryzujące się takimi samymi lub też innymi kosztami. Takie trasy są uznawane za najlepsze i pozbawione zapętleń ścieżki prowadzące do danego miejsca docelowego.
Jak wspomniałem powyżej, protokół EIGRP wykorzystuje wektor odległości, ale także działa jako protokół stanu łącza, ponieważ wysyła częściowe przyrostowe aktualizacje tras routingu do sąsiednich routerów (wymagających informacji zawartych w częściowych aktualizacjach) i efektywnie wykorzystuje pasmo, a zarazem przechowuje informacje o routingu. Takie działanie protokołu EIGRP w dobrze skonfigurowanej sieci tylko w minimalnym stopniu obciąża pasmo, co jest bardzo dużą zaletą tego protokołu.
Ponadto do obsługi innych protokołów sieciowych, takich jak, np. IP, IPX, czy Apple Talk, protokół EIGRP wykorzystuje moduł PDM i w praktyce może zastępować protokoły IPX-RIP oraz IPX-SAP oraz przejmować funkcje protokołu RTMP w ramach protokołu AppleTalk, co pozytywnie wpływa na funkcjonowanie sieci.
Routery obsługujące protokół EIGRP tworzą relacje przylegania, czyli dynamicznie dowiadują się o nowych trasach, które powstały w sieci, wykrywają niedostępne i niedziałające routery oraz potrafią ponownie wykryć routery, które wcześniej były niedostępne.
Natomiast sama komunikacja oparta o protokół EIGRP opiera się na protokole warstwy transportowej RTP (Reliable Transport Porotocol), gwarantującym dostarczenie pakietów EIGRP do wszystkich sąsiednich routerów w odpowiedniej kolejności. Jednocześnie w sieciach opartych na protokole IP do wyznaczenia kolejności pakietów EIGRP i zapewnienia ich właściwego i prawidłowego dostarczenia routery wykorzystują protokół TCP. Taka konstrukcja powoduje, że protokół EIGRP jest niezależny od protokołu bazowego.
W tym miejscu warto jeszcze zaprezentować algorytm DUAL, a dokładniej DUAL FSM, który jest automatem skończonym i maszyną abstrakcyjną. Definiuje on zbiór możliwych stanów oraz zdarzeń wywołujących te stany i zdarzeń będących efektami tych stanów. Algorytm DUAL używa maszyny abstrakcyjnej FSM wówczas gdy aktualny sukcesor (trasa z najniższą metryką) ulegnie awarii lub metryka jego trasy ulegnie zwiększeniu (nie będzie już najniższa). Logika automatu skończonego FSM wygląda następująco:
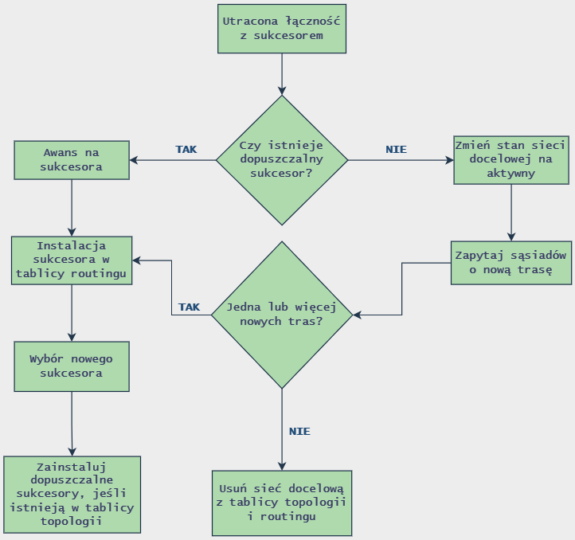
Algorytm opiera się o potencjalną awarię sukcesora, czyli dezaktualizację trasy z najniższą metryką. W takim przypadku router sprawdza w tablicy topologii, czy posiada dopuszczalny sukcesor (kolejną trasę z najniższą metryką). Jeśli tak jest, to taka trasa awansuje na nowego sukcesora, dzięki czemu zapewniony jest wysoki czas zbieżności. Jeżeli taki sukcesor nie istnieje w tablicy topologii, wówczas podsieć znajdująca się w stanie pasywnym zmienia stan na aktywny, a metryka opłacalnej odległości zostaje ustawiona na maksymalną wartość oznaczającą nieskończoność. W takim przypadku algorytm DUAL będzie aktywnie odpytywał sąsiednie routery o nowy sukcesor, co jest dokonywane poprzez rozsyłanie zapytania EIGRP Query. Po wysłaniu tego zapytania router czeka na odpowiedź przez 180 sekund. Jeżeli otrzyma informację zwrotną zawierającą alternatywną trasę, to ponownie ustanawia podsieć w stan pasywny, a podana trasa z najniższą metryką zostaje sukcesorem. Jest to możliwe, ponieważ metryka opłacalnej odległości starej trasy (dawnego sukcesora) została ustawiona na nieskończoność, wobec czego metryka nowej trasy zawsze będzie niższa, wobec czego zostanie nowym sukcesorem, nawet jeśli wcześniej nie spełniała ku temu warunku (nie posiadała najniższej metryki).
Protokół EIGRP do utrzymywania tabel i nawiązywania relacji z sąsiadującymi routerami wykorzystuje różne rodzaje komunikatów (pakietów), do których można zaliczyć:
- hello – komunikat ten służy do wykrywania, weryfikowania i ponownego wykrywania sąsiednich routerów i jest wysyłany w stałych, konfigurowalnych odstępach czasu, które są zależne od szerokości pasma interfejsu; natomiast w sieciach IP pakiety (komunikaty) te wysyłane są pod adres grupowy 224.0.0.10,
- acknowledgement (potwierdzenie) – komunikat ten służy do poinformowania o otrzymaniu pakietu EIGRP w ramach komunikacji gwarantowanej na podstawie protokołu RTP; natomiast potwierdzeniami są rozsyłane pojedynczo pakiety hello, które mogą być dołączane do innych rodzajów pakietów (komunikatów EIGRP), np. komunikatów odpowiedzi,
- update (aktualizacja) – komunikat ten służy do wysyłania (z gwarancją) pakietów aktualizacyjnych do wykrytego nowego routera sąsiedniego; pakiety (komunikaty) te są wysyłane w trybie transmisji pojedynczej (unicast) i umożliwiają nowemu routerowi uzupełnienie tablicy topologii; natomiast w przypadku wykrycia zmian w topologii router wysyła komunikat (pakiet) do wszystkich sąsiadów w trybie multiemisji (multicast) informujący o zaistniałej zmianie,
- query (zapytanie) – komunikat ten służy do ustalenia innej podstawowej trasy do miejsca docelowego, po utracie dotychczasowej trasy (patrz opisany wyżej algorytm DUAL FSM) i jest rozsyłany (z gwarancją) grupowo do wszystkich sąsiednich routerów,
- reply (odpowiedź) – komunikat ten służy do udzielenia odpowiedzi na zapytanie (query) przez sąsiednie urządzenia; komunikat ten zawiera informacje o dostępnych trasach albo stwierdzenia braku żądanych informacji i jest wysyłany (z gwarancją) przy użyciu transmisji pojedynczej.
Protokół EGP
Protokół EGP (Exterior Gateway Protocol), czyli protokół bramy zewnętrznej, jest przestarzałym, stworzonym w 1982 roku protokołem routingu służącym do łączenia autonomicznych systemów (AS) oraz do wymiany informacji pomiędzy bramami internetowymi należącymi do tego samego lub różnych systemów autonomicznych (AS). W latach ’80 XX wieku protokół ten był często stosowany przez uniwersytety, instytuty badawcze, organizacje prywatne oraz organizacje rządowe, lecz został wyparty przez protokół BGP (Border Gateway Protocol), który opisałem poniżej.
Natomiast protokół EGP został pierwotnie zaprojektowany w celu komunikowania dostępności głównych routerów Agencji Zaawansowanych Projektów Badawczych Stanów Zjednoczonych (ARPANET). Informacje były przekazywane z poszczególnych węzłów źródłowych w odrębnych domenach administracyjnych Internetu, zwanych automatycznymi systemami (AS) do głównych routerów, które przekazywały te informacje przez szkielet (sieć szkieletową), zanim mogły być przekazane (informacje) do sieci docelowej w innym autonomicznym systemie (AS).
Warto dodać, że w przeciwieństwie do większości innych protokołów, protokół EGP koncentruje się na osiągalności sieci i nie bierze pod uwagę żadnych wskaźników przy obliczaniu najlepszej trasy. Sama wymiana informacji zachodziła w trzech krokach:
- neighbour acquisition – w tym kroku są pozyskiwane informacje o sąsiednich routerach poprzez wymianę odpowiednich komunikatów,
- neighbour reachability – w tym kroku zachodzi sprawdzanie dostępności sąsiednich routerów, co polega na wysłaniu odpowiedniego komunikatu i oczekiwaniu na odpowiedź; jeśli odpowiedź nie zostanie udzielona po trzykrotnym wysłaniu komunikatu, dany router sąsiedni zostaje uznany za nieaktywny i wszystkie informacje dotyczące osiąganych przez niego tras są usuwane z tablicy routingu,
- network reachability – w tym kroku sprawdzana jest osiągalność adresu wewnętrznej sieci autonomicznej, co jest wykonywane przez okresowe przesyłanie danych o dostępnych adresach wewnątrz autonomicznej sieci (AS).
Z uwagi na to, że protokół EGP nie jest już powszechnie stosowany, poprzestanę na powyższym opisie tego protokołu.
Protokół BGP
Protokół BGP (Border Gateway Protocol) jest zewnętrznym protokołem trasowania, a jego wersja czwarta jest najczęściej spotykanym protokołem routingu we współczesnym Internecie. Warto zaznaczyć, że protokół ten ma wiele rozszerzeń, które są stosowane przy implementacji, m.in.: MPLS VPN, Multicast VPN, czy IPv6. Nagłówek protokołu BGP wygląda następująco:

BGP jest otwartym protokołem wektora ścieżki, tworzącym niezapętlone trasy (ścieżki) pomiędzy rożnymi autonomicznymi systemami (AS). Jego obecna wersja (BGP-4) została opisana w dokumentach RFC 1771 oraz RFC 4271. Co ciekawe protokół ten do ustalania tras routingu nie używa tradycyjnych metryk, ale opiera się na atrybutach i wbudowanym algorytmie wyboru, co pozwala na pełną redundancję w połączeniu z Internetem oraz na łączenie dwóch autonomicznych systemów (AS) w celu wymiany ruchu pomiędzy tymi systemami.
Do swojego funkcjonowania protokół BGP wykorzystuje protokoły warstwy 4 (warstwy transportu) modelu ISO/OSI i pracuje na porcie TCP o numerze 179. Dzięki takiej konstrukcji aktualizacje tras routingu są wysyłane w sposób niezawodny, a sam protokół BGP nie potrzebuje używać mechanizmów retransmisji czy segmentacji. Routery pracujące na protokole BGP zestawiają pomiędzy sobą odpowiednią sesję, co pozwala na wymianę informacji o dostępnych trasach (prefiksach) oraz na wyznaczanie najlepszych niezapętlonych tras do sieci docelowych.
Routery pracujące na protokole BGP wymieniają pełną tablicę trasowania jedynie podczas początkowej sesji BGP (każdy router posiada swoją własną tablicę BGP), a każda zmiana topologii sieci powoduje wysłanie zawiadomienia o aktualizacji. Natomiast routery utrzymują sesje poprzez przesyłanie wiadomości typu „keepalive” oraz obsługują VLSM i podsumowanie, zwane bezklasowym trasowaniem międzydomenowym (Classes Inter-Domain Routing, CIDR).
Ponadto każdy zestaw tras routingu przesyłany protokołem BGP jest opisywany zestawem atrybutów. Atrybuty przesyłane są w komunikatach aktualizacyjnych (UPDATE) i pozwalają na większą elastyczność oraz podejmowanie złożonych decyzji dotyczących wyboru najlepszej trasy. W protokole BGP zdefiniowane są następujące atrybuty trasy (ścieżki):
- standardowe (well-known) i niestandardowe, przy czym atrybuty standardowe muszą być rozumiane przez wszystkie implementacje protokołu BGP,
- obowiązkowe i opcjonalne, przy czym część ze standardowych atrybutów jest obowiązkowa i musi być podana w opisie trasy (ścieżki), natomiast wszystkie atrybuty niestandardowe są opcjonalne,
- przechodnie i nieprzechodnie, przy czym atrybut przechodni jest przekazywany do innych routerów – wszystkie atrybuty standardowe są przechodnie, natomiast atrybuty opcjonalne mogą być przechodnie (w takim przypadku router przekazuje atrybut do innych routerów sąsiednich, nawet jeżeli interpretacja protokołu BGP tego routera nie implementuje takiego atrybutu) lub nieprzechodnie (w takim przypadku router może zignorować taki atrybut).
W związku z powyższym warto zaprezentować najważniejsze atrybuty używane w komunikacji BGP:
- ORIGIN (Pochodzenie) – jest to atrybut standardowy i obowiązkowy, którego kod wynosi 1, atrybut ten określa źródło ścieżki i może przyjąć jedną z następujących wartości:
– IGP, czyli pochodzący z wewnątrz danego autonomicznego systemu (AS),
– EGP, czyli otrzymany z EGP (protokołu bramy zewnętrznej),
– niepełny (incomplete), czyli wykrycie trasy BGP nastąpiło przez redystrybucję lub routery statyczne; - AS_PATH – jest to atrybut standardowy i obowiązkowy, którego kod wynosi 2, atrybut ten opisuje ciąg autonomicznych systemów (AS), będących ścieżką do docelowej sieci IP;
- NEXT_HOP (Następny skok) – jest to atrybut standardowy i obowiązkowy, którego kod wynosi 3, atrybut ten opisuje adres następnego skoku ze zdalnej ścieżki (trasy);
- MULTI_EXIT_DISC (Multi Exit Discriminator, Wyróżnik wielowyjściowy) – jest to atrybut niestandardowy i nieprzenośny, którego kod wynosi 4, atrybut ten informuje routery równorzędne, obsługujące protokół BGP, w innych autonomicznych systemach (AS) o ścieżce (trasie), którą należy podążać do określonego autonomicznego systemu w przypadku istnienia wielu połączonych systemów autonomicznych – wówczas preferowana jest niższa wartość MED;
- LOCAL_PREF (Lokalna preferencja) – jest to atrybut standardowy i opcjonalny, którego kod wynosi 5, atrybut ten wskazuje preferowaną ścieżkę (trasę) wyjścia z danego autonomicznego systemu (AS) – w takim przypadku preferowana jest wyższa lokalna preferencja;
- ATOMIC_AGGREGATE (Niepodzielny agregat) – jest to atrybut standardowy i opcjonalny, którego kod wynosi 6, atrybut ten informuje routery obsługujące protokół BGP o dokonanej agregacji tras, natomiast nie jest używany przy wyborze routera;
- AGGREGATOR (Agregator) – jest to atrybut niestandardowy i przenośny, którego kod wynosi 7, atrybut ten jest identyfikatorem routera odpowiedzialnego za agregację i nie jest używany przy wyborze routera;
- COMMUNITY (Okolica) – jest to atrybut niestandardowy i przenośny, którego kod wynosi 8, atrybut ten pozwala na znakowanie tras i użycie grup tras o takich samych cechach charakterystycznych – jeżeli atrybut ten jest wykonywany po stronie ISP, to zwykle znakuje ruch do klientów oraz niektóre grupy prefiksów;
- ORIGINATOR_ID (Identyfikator źródła) – jest to atrybut opcjonalny i nieprzenośny, którego kod wynosi 9, atrybut ten służy zapobieganiu powstawania pętli routingu;
- Cluster list (Lista klastrów) – jest to atrybut opcjonalny i nieprzenośny, którego kod wynosi 10, atrybut ten występuje w formie listy używanej w środowisku route reflectorów i jest używany do zapobiegania powstawania pętli routingu.
Warto dodać że protokół BGP identyfikuje automatyczne systemy (AS) na podstawie ich numerów (numerów AS, ASN), które są przyznawane przez organizację RIR (Regional Internet Register). Aktualnie (od 2007 roku) numery ASN są wielkości 32 bitów (4 bajtów), dzięki czemu została znacznie zwiększona przestrzeń dostępnej numeracji, przy jednoczesnym zachowaniu pełnej kompatybilności ze starszym 16 bitowym (2 bajtowym) formatem numeracji, dzięki czemu nie trzeba było zmieniać oprogramowania na routerach obsługujących straszy format numeracji.
Natomiast sam protokół BGP dzieli się na dwa rodzaje, a mianowicie:
- EBGP (Exterior Border Gateway Protocol) używany podczas sesji pomiędzy dwoma różnymi autonomicznymi systemami (AS), oraz
- IBGP (Interior Border Gateway Protocol) używany podczas sesji pomiędzy dwoma routerami brzegowymi w obrębie jednego autonomicznego systemu (AS).
Sam protokół wymiany informacji przez routery jest taki sam dla protokołu EBGP oraz protokołu IBGP. Jednakże routery inaczej interpretują trasy routingu, przekazane protokołem BGP, odnoszące się do własnego lub zewnętrznego autonomicznego systemu (AS). Trasy wewnętrzne, o których informacja została przekazana protokołem IBGP co do zasady mają bardzo niski priorytet, dzięki czemu do optymalizacji tras wewnątrz jednego autonomicznego systemu (AS) mogą być używane wewnętrzne protokoły routingu (zaliczane do protokołów IGP). Warto podkreślić, że w implementacjach protokołu BGP stosujących tzw. dystans administracyjny, czyli parametr określający priorytet ważności tras otrzymanych za pośrednictwem określonego protokołu routingu (źródła) odpowiednio domyślnie jest ustawiany dystans w zależności od tego, czy trasa jest zewnętrzna i informacja o niej jest przekazywana protokołem EBGP, czy jest to trasa wewnętrzna, o której informacja została przekazana protokołem IBGP. W przypadku tras zewnętrznych domyślnie dystans jest ustawiany na wysoki priorytet (np. 20), natomiast dla tras wewnętrznych domyślny dystans jest ustawiany na bardzo niski priorytet (np. 200). To samo dotyczy ustanawiania przez routery atrybutów tras przy wysyłaniu ich aktualizacji (tras routingu) protokołem EBGP lub protokołem IBGP.
Wracając jeszcze do sesji, dzięki którym zachodzi wymiana informacji o trasach routingu, to mogą one być zestawione pomiędzy routerami bezpośrednio ze sobą połączonymi, pracującymi na brzegach autonomicznego systemu lub pomiędzy zdalnymi routerami (tzw. sesje BGP multihop). Sesje multihop najczęściej wykorzystywane są w komunikacji IBGP i zdecydowanie rzadziej w komunikacji odbywającej za pośrednictwem protokołu EBGP, gdyż najczęściej do prawidłowego działania wymagają wsparcia przez inne protokoły trasowania dynamicznego lub trasowania statycznego, co wynika z konieczności nawiązania komunikacji TCP z sąsiednim routerem działającym na protokole EBGP. W związku z tym, w przypadku braku trasy pochodzącej z innego źródła, nie ma możliwości zestawienia sesji BGP.
Protokół BGP co do zasady pracuje w sieciach redundantnych, które umożliwiają osiągnięcie sieci docelowej kilkoma różnymi trasami. Gdy protokół BGP otrzyma wiele tras (ścieżek) do określonego celu w zdalnej sieci, wówczas musi wybrać najlepszą trasę, co przejawia się w porównywaniu, zgodnie z przedstawionym poniżej algorytmem, prefiksów poszczególnych ścieżek, a dokładniej ich atrybutów.
Zgodnie z algorytmem wyboru najlepszej trasy, w pierwszej kolejności dokonywane jest sprawdzenie atrybutów w ich kolejności. Jeżeli porównywany atrybut ma taką samą wartość we wszystkich ścieżkach, czyli opcjach dojścia do prefiksu, to algorytm porównuje kolejny atrybut. Atrybuty są porównywane w celu odnalezienia pierwszego wystąpienia nierównych parametrów, co umożliwia wybranie najlepszej ścieżki, przy czym należy pamiętać, że protokół BGP nie bierze pod uwagę jakości połączenia, natomiast zawsze propaguje najlepszą ścieżkę do wszystkich routerów równorzędnych.
W celu lepszego zobrazowania działania przedmiotowego algorytmu, przedstawię sposób działania algorytmu wyboru trasy stosowanego przez routery Cisco obsługujące protokół BGP:
- Preferuj najwyższą wagę (WEIGHT, jest to lokalny parametr routingu opartego na protokole BGP specyficzny dla urządzeń Cisco – nie jest przesyłany do innych routerów).
- Preferuj najwyższy LOCAL_PREF.
- Preferuj trasy ogłoszone lokalnie przez komendę network lub redistribute.
- Preferuj ścieżkę z krótszym AS_PATH (czyli mniejszą liczbą systemów autonomicznych w danej ścieżce).
- Preferuj niższy ORIGIN.
- Preferuj niższy MED.
- Preferuj ścieżki EBGP nad IBGP.
- Preferuj ścieżki, gdzie koszt IGP do BGP next-hop’a (następnego skoku) jest niższy.
- Jeżeli włączony jest BGP multipath to zainstaluj trasę w tablicy routingu.
- Preferuj starszą ścieżkę (otrzymaną wcześniej).
- Preferuj ścieżkę, która ma niższy router-id.
- Preferuj ścieżkę, która przyszła od sąsiada (neighbor) z niższym adresem IP.
Autonomiczne systemy (AS) obsługujące komunikację opartą na protokole BGP mogą rozgłaszać określoną liczbę adresów IP zgrupowanych w prefiksy. Na przykład dana strona internetowa (xyz[.]pl) ma adres IP 2.22.120.200 i rozgłasza prefiks 2.22.120.0/21 (zakres IP 2.22.120.0 – 2.22.127.255) pod AS o numerze 10120. Warto dodać, że liczba prefiksów w Internecie stale rośnie wraz liczbą używanych adresów IP i wyczerpywaniem się adresacji, co powoduje konieczność dzielenia bloków adresowych na mniejsze.
Natomiast typowym zastosowaniem protokołu BGP jest routing w sieci posiadającej styki internetowe z dwoma lub większą liczbą dostawców Internetu (Internet Service Providers, ISP), a sam protokół BGP posiada długi czas zbieżności, co wyraża się w tym, że pobranie pełnej tablicy routingu Internetu może potrwać wiele godzin, tak samo jak rozpowszechnienie nowego wpisu z tablicy routingu w całej sieci.
Protokół IS-IS
Protokół IS-IS (Intermediate System to Intermediate System) – jest otwartym protokołem trasowania stanu łącza (link-state) a zarazem jako protokół bramy wewnętrznej zaliczany jest do grupy protokołów IGP (Internal Gateway Protocol). Używany jest wewnątrz autonomicznego systemu (AS) i został opisany w dokumencie RFC 1142.
Protokół został opracowany tak, aby wykorzystywać informacje o stanie łącza do podejmowania decyzji o trasach routingu, a jednocześnie stanowić protokół routingu dla CLNP (Connectionless Network Protocol). Ponadto w wersji Dual IS-IS (Integrates IS-IS) wspiera routing IP i CLNP.
Protokół ten działa wewnątrz jednego autonomicznego systemu (AS), w ramach którego można wyróżnić systemy końcowe będące tymi elementami sieci komputerowej, które wysyłają i odbierają i przekazują pakiety, czyli np. routery i hosty – to właśnie one są określane mianem Intermediate Systems.
Warto podkreślić, że w ramach protokołu IS-IS dochodzi do podziału sieci na mniejsze obszary (area), w których zawierają się systemy pośredniczące (Intermediate Systems). Tymi obszarami są:
- Level 1 – do tego obszaru zalicza się wewnętrzne routery z danego obszaru, w związku z czym routery te znają jedynie topologię swojego obszaru,
- Level 2 – do tego obszaru zalicza się routery szkieletowe (backbone), które posiadają informację o topologii swojego obszaru oraz o trasach spoza swojego obszaru,
- Level1 / Level2 – do tego obszaru zalicza się routery, które działają jednocześnie jako routery wewnątrz danego obszaru (routery wewnętrzne) oraz jako routery szkieletowe (backbone).
W tym miejscu należy wyraźnie zaznaczyć, że routery z obszaru Level 1 nigdy nie sąsiadują z routerami z obszaru Level 2 i na odwrót, mianowicie routery z obszaru Level 2 nigdy nie są sąsiadami routerów z obszaru Level 1. Do powstania sąsiedztwa pomiędzy routerami z obszaru Level 1 konieczne jest, aby ich Area ID (numer obszaru) było takie samo. Jednocześnie do powstania sąsiedztwa pomiędzy routerami z obszarów Level 2 numery obszarów nie muszą być identyczne.
Do komunikacji protokół IS-IS wykorzystuje pakiety (komunikaty) PDU, których format wyglądają następująco:

W ramach protokołu IS-IS można wyróżnić następujące komunikaty PDU:
- IS-IS Hello PDU – komunikat ten służy do odkrywania i identyfikacji sąsiednich routerów, a zarazem określa czy sąsiad należy do obszaru Level 1 czy Level 2; komunikat ten dzieli się na dwa rodzaje, mianowicie Point-to-Point Hello PDU oraz LAN hello PDU (przy czym dzieli się on na Level 1 hello PDU i Level 2 hello PDU),
- Link-state PDU – w komunikacie tym jest zawarta informacja o stanach sąsiadujących ze sobą systemów IS-IS; komunikaty te wysyłane są w określonych odstępach czasu, a także w przypadkach szczególnych, takich jak pojawienie się nowego sąsiada (sąsiedniego routera), zniknięcie sąsiedniego routera (np. na skutek awarii) lub w przypadku zmiany kosztu linku,
- Complete sequence numer PDU (CSNP) – komunikat ten jest wysyłany w ramach wszystkich połączeń i jest wykorzystywany do aktualizacji i synchronizacji bazy LSP (Link-state PDU),
- Partial sequence number PDU – komunikat ten jest wykorzystywany do żądania aktualizacji LSP (Link-state PDU) i do potwierdzenia dostarczenia tych komunikatów,
- TLV (Type/Length/Values) – komunikat ten stanowi strukturę wykorzystywaną przez PDU do zapisu informacji związanych z routingiem, w związku z czym za pomocą tego komunikatu może być przekazywana nazwa (hostname) routera do sąsiadujących routerów, jak również informacje związane z MPLS-TE, czyli techniką stosowaną przez routery, w której trasowanie pakietów zostało zastąpione przez tzw. przełączanie etykiet (w praktyce technika ta jest stosowana jedynie w ramach protokołu IP).
Protokół IS-IS używa adresacji ISO, a interfejsy posiadające taką adresację nazywane są NSAP (Network Service Access Point). Aby lepiej zrozumieć działanie protokołu IS-IS warto przedstawić jak wygląda adres ISO oraz jakie elementy wchodzą w jego skład. Elementami tymi są:
- Area ID – czyli numer obszaru, który składa się z dwóch części: pierwszej przyjmującej wartość od 1 do 13 bajtów oraz drugiej przyjmującej wartość od 0 do 12 bajtów,
- System ID – stanowi unikalną wartość w całym autonomicznym systemie (AS), zazwyczaj tą wartością jest adres MAC lub adres IP zapisany za pomocą BCD (Binary Code Decimal) – jako przykład można wskazać adres IP 192.168.100.120, który w BCD będzie zapisany jako 1921.6810.0120,
- N-selector – jest to wartość wykorzystywana, jeżeli system końcowy ma wiele adresów NSAP.
Mając powyższe na uwadze pełny adres ISO może przyjąć następujący wygląd:

Protokół IS-IS często jest stosowany w dużych sieciach komputerowych z uwagi na dużą skalowalność oraz niskie obciążenie łącz oraz możliwość zastosowania routingu IPv6 bez konieczności konfigurowania dodatkowego, dedykowanego protokołu. Ponadto protokół ten używa algorytmu Dijkstry’ego do odnalezienia najlepszej trasy do punktu docelowego.
Najpopularniejsze ataki na dynamiczne protokoły routingu
Z uwagi na to, że poruszamy się w dziedzinie cyberbezpieczeństwa, pokrótce zaprezentuję przykładowe ataki, jakie mogą być przeprowadzone na dynamiczne protokoły routingu.
Do najczęściej przeprowadzanych ataków można zaliczyć:
- spoofing usługi routingu (ARP Spoofing), który polega na takiej podmianie lub modyfikacji tablicy routingu, aby dane przesyłane były do miejsc docelowych kontrolowanych przez hakera, a nie tych, do których miały pierwotnie dotrzeć,
- atak DDoS typu ICMP flooding (zalewanie pakietami ICMP) w warstwie 3 (warstwie sieci) modelu ISO/OSI, zawierającej informacje dotyczące routingu i przełączania w sieciach, w związku z czym atak ten może mieć wpływ na przepustowość sieci i dołożyć dodatkowe obciążenie na firewall’a.
Nie będę bardziej szczegółowo pisał o tych atakach, ponieważ zostały one dokładnie opisane i zaprezentowane w artykule dotyczącym ataków DDoS oraz w przewodniku po ataku Man-in-the-Middle, w którym gruntownie opisuję atak ARP Spoofing.
Podsumowanie
Dzięki routingowi dynamicznemu oraz obsługującym go poszczególnym protokołom możliwy był rozwój współczesnego Internetu. Pojawianie się nowych tras, zanikanie starych oraz ciągłe zmiany w topologiach sieci oraz w międzysieci spowodowały konieczność opracowania automatycznego informowania się routerów pomiędzy sobą o trasach routingu – właśnie w tym celu powstał model routingu dynamicznego, dzięki któremu bez udziału administratora sieci możliwe jest wykrywanie zdalnych sieci, zachowywanie aktualnej informacji o trasach, wybór najlepszej trasy do sieci docelowej, czy umiejętność znalezienia nowej najlepszej trasy, w przypadku gdy bieżąca trasa zanika (przestaje być dostępna). Do realizacji tych celów stosuje się różne, opisane powyżej protokoły, które opierają się na wspólnych komponentach, takich jak struktury danych (tablice routingu lub bazy danych), wiadomości protokołów routingu (którymi są pakiety, komunikaty służące do określenia sąsiednich routerów, wymiany informacji o trasach oraz utrzymaniu aktualnej informacji o sieci), a także algorytmy (służące do określenie najlepszej trasy dla danej sieci docelowej).
Mając powyższe na uwadze routing dynamiczny stał się immanentną cechą sieci komputerowych oraz podstawą do wymiany danych pomiędzy routerami zarówno pracującymi w tej samej sieci, jak i w sieciach odległych.
Autor: Michał Mamica